簡單回顧
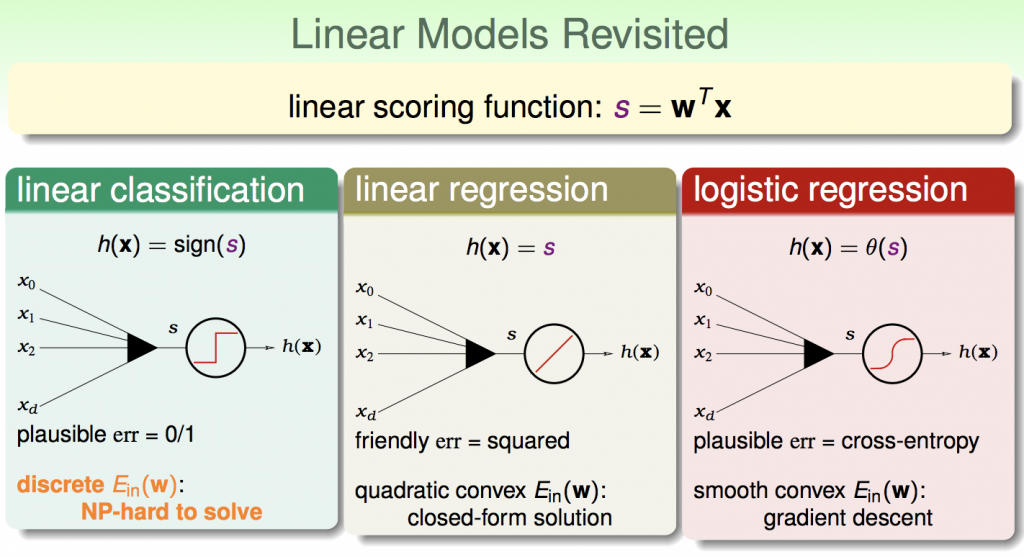
在前面章節有做linear classification、linear regression、logistic regression的介紹,共同點為利用加權的方式計算出分數。從下面的圖可以得知,linear classification在計算error是 NP hard 問題(無法用polynominal解決),在電腦科學領域已經被證明,很難用程式來解決這個問題。
Error Function
假設現在我們的資料是要做binary classification的資料,也就是label y不是+1就是-1,我們把三種models統整一下,整理成 ys 的形式,方便後續做比較。
接下來,我們把上面三種方法畫圖做比較,以 ys 為橫坐標,error 為縱坐標,把這三個函數畫出來(以下是看圖說故事)。

三種方法做分類的優缺點
整體來說,logistic regression比較好,在資料通常不是線性可風的情況下時,比較常使用 Logistic Regression。


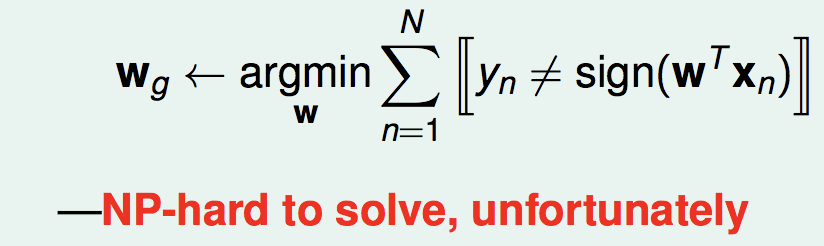
 iThome鐵人賽
iThome鐵人賽